
Personalized Web Agent
[DAVIAN Lab 개별연구] 사용자의 web 탐색 history로부터 preference를 추론해 personalized web task를 수행하는 web agent benchmark 설계와 평가 데이터셋 구축 및 개선된 agent 구현
🗺️ Overview
LLM 기반 web agent의 연구가 활발해지면서, 대부분의 web agent는 사용자가 시키는 지시사항을 대체로 잘 반영하고 있습니다. 그러나 실제 웹 환경에서 사용자들은 자신이 바라는 것들이나 개인의 선호를 query에 명확하게 명시하지 않는 경우가 훨씬 많습니다. 이는 사람 입장에서 agent가 자신과 맥락을 이미 공유하고 있다고 생각해서이기도 하고, 자신의 웹 탐색 선호를 말로 explicit 하게 표현하지 못하기 떄문이기도 합니다. 이에 저희는 task 수행 능력을 넘어, Agent가 사용자 개인의 맥락을 얼마나 잘 포착하고 반영하는가에 집중해서 연구를 진행하고 있습니다. 기존 벤치마크는 모호한 쿼리와 personalization을 전혀 고려하지 않아, 이를 제대로 평가할 수 있는 기반이 존재하지 않습니다.
DAVIAN Lab 소속 박사과정 학생분과 공동 1저자로 협업하여, 사용자의 web browsing history로부터 preference를 추론하고 모호한 쿼리 상황에서 개인화된 web task를 수행하는 personalized web agent를 연구하고 있습니다. 구체적으로는 이를 평가하기 위한 (1) benchmark 설계 및 데이터셋 구축과, (2) preference 추론 능력을 갖춘 개선된 agent 구현을 함께 진행하고 있습니다.
(1) Benchmark 설계 및 데이터셋 구축에서는 Preference 정의, 평가 지표 정의 등을 맡았으며, web 데이터셋을 직접 구축했습니다. (2) 개선된 agent 구현은 제가 주도적으로 진행하고 있으며, 구체적으로는 선호를 저장하는 두 단계의 메모리 시스템을 설계 및 구현했고, 실험 설계 및 baseline 비교를 진행하고 있습니다.
⏰ Problem & Task
기존 web agent 벤치마크(Mind2Web, WebArena 등)는 사용자가 원하는 바를 명확하게 명시한 쿼리를 전제로 설계되어 있어, personalization을 전혀 고려하지 않습니다. 실제 사용자는 “괜찮은 노트북 찾아줘”처럼 모호한 쿼리를 던지는 경우가 많고, 이때 agent가 사용자의 취향과 맥락을 반영해 행동해야 하는지를 평가할 수 있는 벤치마크 자체가 존재하지 않았습니다.
이 연구에서 해결하고자 하는 목표는 두 가지입니다.
- 벤치마크 설계: ambiguous query 상황에서 personalization 능력을 평가할 수 있는 벤치마크와 데이터셋을 구축하는 것
- Agent 개선: 사용자의 web history로부터 preference를 추론하고, 이를 실시간 task 수행에 활용할 수 있는 agent를 구현하는 것
🔭 Approach
[벤치마크 디자인]
이러한 gap을 채우기 위해서, 저희는 현실성과 다양성을 고려한 벤치마크를 제안하려고 합니다. Open Web Environment에서의 Realistic Historical Data를 바탕으로, Web Agent Benchmark를 설계했습니다.
우선 Personlization을 고려하기 위한 Web Task를 사용자의 선호를 파악하기 위한 Preference Task 와 사용자가 지칭하는 과거의 행동을 기억하고 재현하기 위한 Memorization Task로 나누었습니다. 또한, 하나의 website만을 탐색하는 기존 web agent benchmark와 다르게, 하나의 intent를 완수하기 위해서 여러 웹사이트를 순차적으로 방문하여 문제를 해결하는 multi-hop query도 함께 고려했습니다.
| Mind2Web / WebArena | PersonalWAB | 본 연구 | |
|---|---|---|---|
| Query 유형 | 명확한 지시 | 일부 모호한 쿼리 | ambiguous query 중심 |
| Personalization | ✗ | △ (제한적) | ✓ (web history 기반) |
| 평가 환경 | 고정 snapshot | 고정 snapshot | Live web |
| 도메인 커버리지 | 특정 사이트 | 제한적 | 23개 category |
Mind2Web·WebArena와 같은 선행연구는 personalization 자체를 다루지 않으며, PersonalWAB은 personalization을 일부 도입했으나 고정된 snapshot 환경에서만 평가합니다. 본 연구는 실제로 동작하는 live web에서 테스트한다는 점에서 재현성과 현실성 측면에서 모두 한 단계 나아간 설정입니다. 도메인은 Similar Web의 taxonomy를 따르는 23개 big category를 커버합니다.
[Preference Memory 모듈]
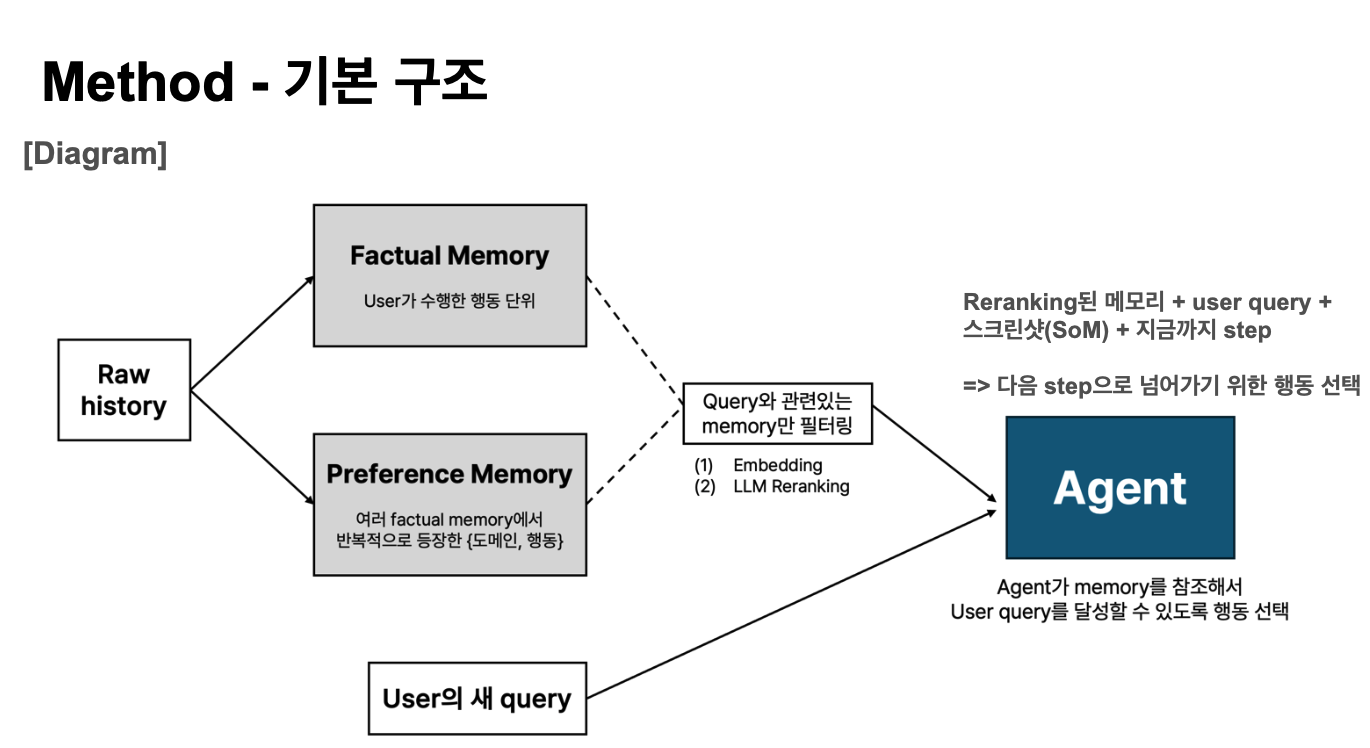 raw web history로부터 preference를 구조화하는 Web Agent 파이프라인을 별도로 설계했습니다. 단순히 history를 LLM에 넣는 방식 대신, 아래와 같은 2단계 메모리 구조를 구성했습니다.
raw web history로부터 preference를 구조화하는 Web Agent 파이프라인을 별도로 설계했습니다. 단순히 history를 LLM에 넣는 방식 대신, 아래와 같은 2단계 메모리 구조를 구성했습니다.
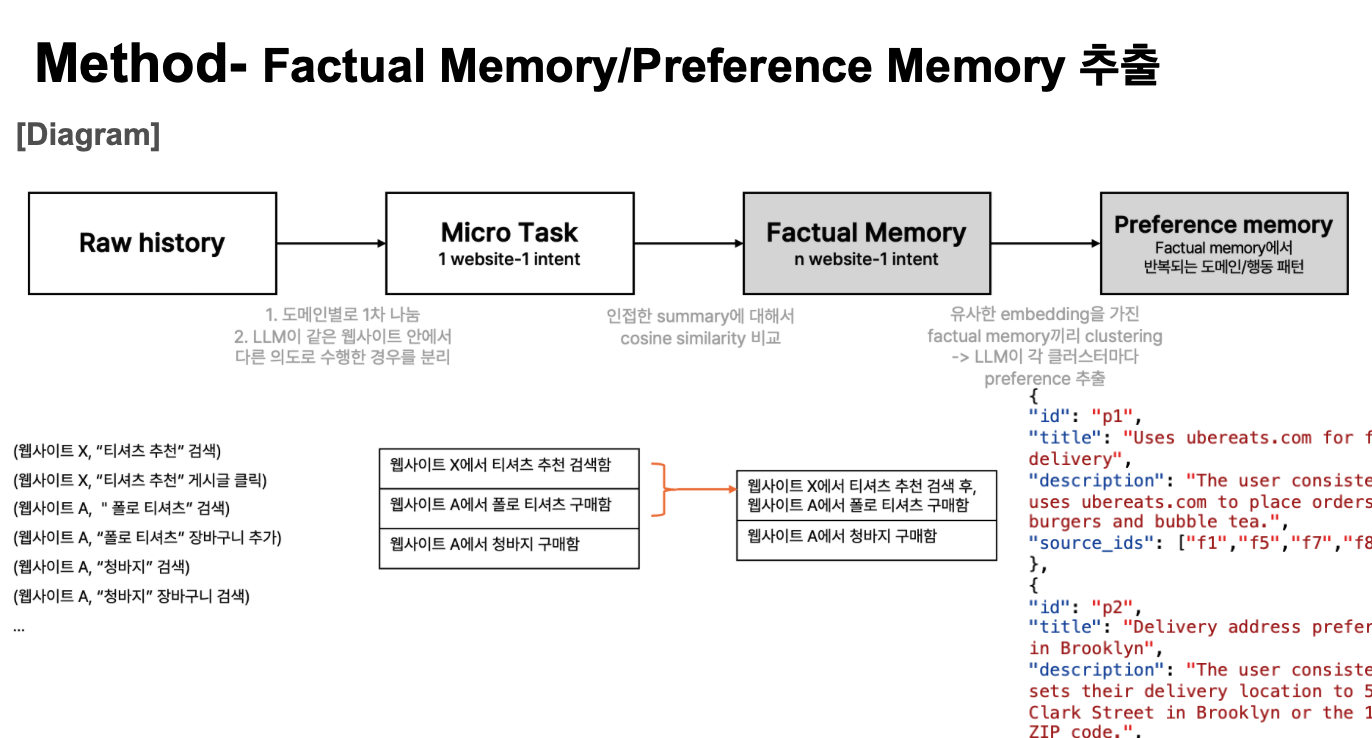
Web History (raw logs)
→ Rule-based 구조화
→ 1 domain × 1 task 분리 (LLM)
→ n domain × 1 task 통합 (embedding)
→ Factual Memory 저장
→ 유사도 클러스터링 → Preference Memory 추출
→ 새 task 입력 시: embedding 검색 + LLM reranking → Agent 행동
- Factual Memory 구성: rule-based로 history를 구조화한 뒤, 1 domain × 1 task 단위로 분리(도메인 단위 절단 → LLM으로 동일 도메인 내 다른 task 분리)하고, 이후 embedding 기반으로 n domain × 1 task 단위로 재통합
- Preference Memory 추출: Factual Memory를 embedding 기반으로 유사도 클러스터링하여, 클러스터 내 반복 행동 패턴을 preference로 추출
새로운 task가 주어지면 embedding 기반 검색 + LLM reranking으로 관련 메모리를 참조해 행동합니다.
[Evaluation Design]
단순히 Web Agent가 query대로 행동했는지 여부를 파악하는 기존의 벤치마크와는 다르게, web agent가 query에 맞게 행동했는지 여부와 함께 사용자의 개인화 여부를 함께 식별합니다. 구체적인 평가 지표는 현재 설계중에 있으나, 현재까지 확정된 내용은 아래와 같습니다.
- Preference Task
- Website Selection Accuracy
- web site 접속 function calling 탐지
- 정답 web site와 몇 개나 일치하는지 판별
- #웹 사이트 일치 개수 / #정답 웹 사이트
- Intent Score 개인화와 무관하게, 태스크 자체가 성공 했는지 평가
- Preference Score 태스크와 무관하게, 개인화 요소를 잘 식별했는지 평가
- Task Success Rate 개인화 Task를 성공적으로 완수 했는지 평가
- number of steps 평균 몇 스텝만에 완수했는지?
- Website Selection Accuracy
- Memorization Task
- History 검색 잘 했는지
- 적절한 관련 history를 잘 검색했는지
- Ground Truth: 관련 raw history 에 대한 F1 측정
- factual memory → source ids 기반으로 F1 측정
- Task Success Rate Task를 성공적으로 완수 했는지 평가
- number of steps 평균 몇 스텝만에 완수했는지?
- History 검색 잘 했는지
🧮 Results
현재 데이터셋 구축 및 agent 구현 단계로, 정량적 수치 비교 실험은 진행 중입니다.
- Live web 환경 기반 benchmark 프로토타입 완성
- 23개 웹사이트를 커버하는 평가 데이터셋 구축 중
- Preference Memory 파이프라인 구현 완료, 평가 실험 준비 중
🤩 Insights
[배운점]
단순히 LLM에 history를 통째로 넘기는 것보다, 구조화된 메모리로 분리·압축하는 과정이 얼마나 중요한지를 설계하면서 체감했습니다. 또한 live web 환경에서의 평가는 reproducibility 문제가 생기기 때문에, 벤치마크 설계 자체가 하나의 연구 기여가 될 수 있다는 점도 배웠습니다.
[한계]
현재 연구가 진행중입니다.